Create Full Stack marries best practices I picked up over a decade developing at large tech companies like Google and Twitter to small startups like MoPub, as well as my own personal projects (Compare Hospitals, Whether°, Flixfindr). At Google, I was impressed with the seamless integration of all the libraries and frameworks. The consistency across Google3 (Google's mono-repo) is incredible. Teams across the entire organization use the same tools with the same style guidelines, and code can be shared and accessed anywhere. When starting a new project, Google developers build on a stable foundation with significant guard rails in place. On the other hand, the tools are very company-specific and focus on performance over developer productivity.
Since leaving Google and returning to the outside world, I've been dismayed that the same solid foundation doesn't exist. It's natural to cobble together solutions following one-off blog posts. A developer's focus isn't - and shouldn't be - infra at an early stage, so hacky solutions tend to win. Unfortunately, as what you're building scales, maintaining these solutions can be a nightmare.
Create Full Stack is my attempt to solve these problems and share my development philosophy. It's inspired by tools like CRA and Expo but applied to the backend, API layer, and dev ops.
Create Full Stack is a continuation of my thoughts and feedback around my featured Medium article One full-stack to rule them all!
Yes, yet another todo example app! 🤦 Needed to throw my hat in the ring because the existing solutions weren’t cutting it.
We want a stack that enables rapid iteration as requirements change without producing bugs. Ideally, it should scale in terms of traffic and developers without requiring costly re-writes.
To achieve this we chose components that are:
A single language, eliminating developer context switching
Type-safe, eliminating a whole class of bugs
Tested at scale in production
Used by enough developers that solutions are easy to find
Coming from Google, I realized the importance of static types across the entire stack (including the API). There are thousands of engineers working on Search and Ads at Google (I was one of them). No one person completely understands the systems because they’ve been built over 10 years by thousands of engineers. Bringing data from the database through the Ad Server and onto Search crossed ~8 different services. Making these changes was scary, to say the least.
Static typing across the stack and a single mono repo are what make this possible. Static typing ensures the data is there and of the expected type when you access it. Mono repo ensures all services are in the same state and the API contracts (Protobufs at Google) are enforced by the compiler. At Google code that doesn’t compile can’t be checked in.
What other typed languages can run on the client and server and aren’t experimental?
Having a single language reduces context switching for engineers. It gives us the confidence to own full-stack changes. TypeScript is rapidly growing in popularity. It’s a superset of JavaScript which is the most popular language of all time so most programmers are at least somewhat familiar with the syntax.
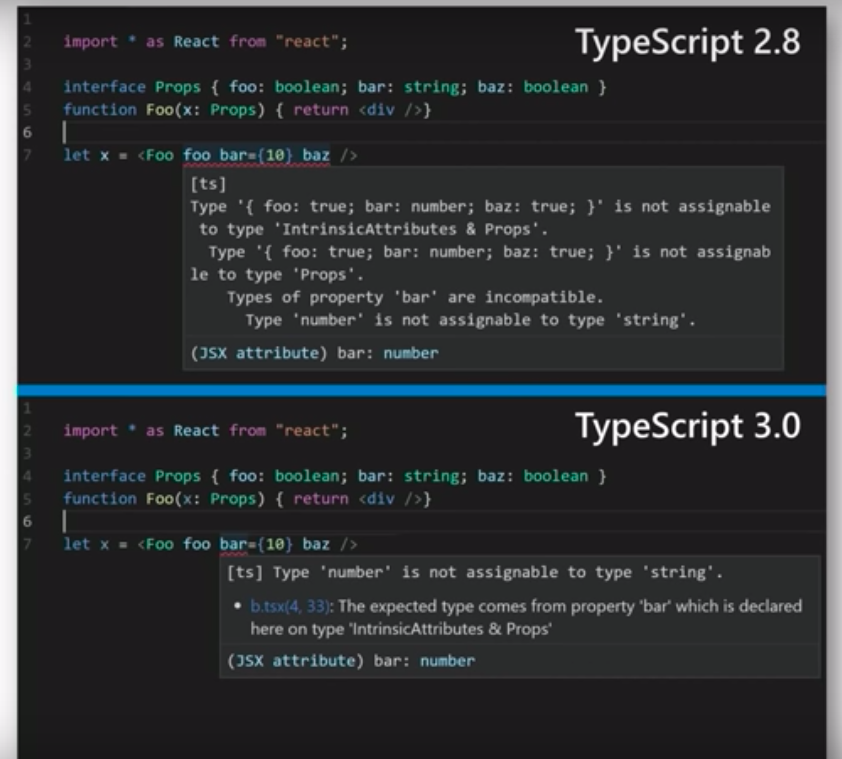
TS eliminates 15% of production bugs. It scales to hundreds, if not thousands, of developers. Microsoft, Google, and countless other companies rely on it in production systems with billions of users. Google is increasingly adopting it over Closure (Google’s prehistoric typed JS language). It has great documentation and IDE support with a thriving community (3rd most loved language on StackOverflow). It presents clear errors when the compiler fails.
It’s 2019! MVC should be dead! Long live JS in templates and one-direction data flow!
JS in templates gives us access to a Turing complete language when we’re constructing what’s displayed. This pushes complexity to the leaves instead of APIs or random custom functions which reduces overall complexity (see Pete Hunt’s talk). In Django (I have a python background pre-React), you’d use tags, filters or write your own custom versions when you run into things like formatting date time ranges. Learning an extra template language and writing complicated escape hatches is a waste!
One way data flow ensures there’s a single source of truth and you don’t run into bugs where the same value could be in different states. Google just announced Compose, a React-like framework, in Android. They dive into the issues with two-way data bindings in their talk at IO.
Since React’s public launch in 2013, it’s only gotten better and grown in popularity. Many of the worlds most used sites are completely or nearly completely written in React (Twitter, Netflix, Uber, Facebook, and Airbnb). Companies that value developer productivity are wise to adopt because it significantly reduces UI code complexity over more traditional frameworks.
GraphQL provides a simple way for clients to request only the data they need and easily move across relationships. Requests can change without server modifications and deploys. Try that with REST or Protobufs!
If we extended our Todo example to have different users we could query for their specific todos. Any additional fields on either user or todo are emitted from the response but could be fetched in different queries without changes to the API
query{
user(id:"xxx"){
name
todos {
name
complete
}
}
}
Apollo has client and server support that requires less upfront learning and setup cost than Relay. It has automated TypeScript type generation through graphql-code-generator. Solid documentation and tooling with a thriving community. Ability to batch queries but can defer until needed, avoiding fragment complexity.
The two major distinctions from a devX perspective I see between Relay and Apollo for queries are containers and cursors. Both are required in Relay (opinionated) and optional in Apollo (flexible).
Container queries batch all query fragments (data required by each component in the subtree) into a single container level query. In the simple Todo list case, this is actually a bit tricky. It involves importing the lower level fragments and composing them up the tree. In Apollo, we’d simply request the data at the component level. The tradeoff is in the number of requests, containers are more efficient at the cost of complexity and difficulty debugging issues.
Cursors are a standard way for pagination in Relay. They require the type you’re fetching to wrap additional details.
Todo GraphQL schema for Relay cursor pagination:
# An object with an ID
interfaceNode{
# The id of the object.
id: ID!
}
# Information about pagination in a connection.
typePageInfo{
# When paginating forwards, are there more items?
hasNextPage: Boolean!
# When paginating backwards, are there more items?
hasPreviousPage: Boolean!
# When paginating backwards, the cursor to continue.
startCursor: String
# When paginating forwards, the cursor to continue.
endCursor: String
}
typeTodoimplementsNode{
# The ID of an object
id: ID!
text: String
complete: Boolean
}
# A connection to a list of items.
typeTodoConnection{
# Information to aid in pagination.
pageInfo: PageInfo!
# A list of edges.
edges:[TodoEdge]
}
# An edge in a connection.
typeTodoEdge{
# The item at the end of the edge
node: Todo
# A cursor for use in pagination
cursor: String!
}
If we’re using Apollo offset based pagination (assuming you have a SQL database this is straightforward), then we just need the Todo type and we pass the limit and offset in the query. The downside is that if new items are inserted or deleted in the original set it can return duplicates or skip results. Cursor based pagination fixes this.
This a simple comparison between Relay and Apollo. For Facebook, Relay’s additional complexities make sense for performance and data guarantees. For us, the added complexity didn’t make sense but it’s something we could revisit.
Our requirement for a single language across client and server limits our server language choices.
Node has some “regrets” like security, the build system, and package.json but, the ecosystem is unparalleled.
Node is by far the most popular language on GAE and AWS Lambda. It’s great for rapid development. However, many companies also use Node at scale in production (Instagram, Netflix, Airbnb, and Walmart).
Is there something else that can run TypeScript on the server safely in production? Unfortunately, Deno (from the creator of Node) isn’t there yet.
While there is never truly one stack to rule them all, we believe that our set of requirements likely matches many people building web apps today. While all of these pieces have been battle tested individually the sum of their parts creates a relatively novel way of developing web apps that isn’t currently well documented.